Backlog Organization

Standardizing the management of the backlog is essential for maintaining clear and highly actionable backlogs. It also allows any Product Manager on the team to understand any project’s backlog with little effort.
Without standardization, it becomes extremely difficult and time-consuming for a Product Manager to understand how a backlog is organized, let alone how the product needs to be developed.
Depending on the project and the client’s requirements, the team might use different tools for backlog management. Regardless of the tool, how the team organizes the backlog revolves around the same concepts. Only their representation varies to adapt to the capabilities of the tool used.
Modules

Modules represent the main components of an application. They are the smallest denominator to which an application can be reduced. Each module contains several features.
For example, a food delivery applications will need an “Order Management” module which will regroup all features that help user place, track, and manage their orders.
In fact, there are several modules that are usually common to most applications: Application (the most generic module in an application), Authentication, and User Profile.
Naming & Slugs
| Example | Name | Label |
|---|---|---|
| Order Management module | Order Management | #order-management |
| Customer Relationship Management module | CRM | #crm |
| Payment gateway module | Payment | #payment |
| Push notifications module | Push Notifications | #push-notifications |
Module names should be as short and accurate as possible. There is no specific pattern for it and it is up to the Product Manager to identify names that fit this ideology best.
In addition to having a name, modules also need a slug for use in labels. The slug is a shorter, more condensed form of the name. Given how short module names are, the slug is typically a hyphenated version of the name.
Features

Features are coherent and standalone groups of user stories that define functionality in the application. A feature must belong to one and only one module (there is a hierarchical relationship between the two).
Module
└── Feature
A feature must be the smallest standalone piece of software which brings business value.
For example, “User can place order” is a feature belonging to the “Order Management” module. So is “User can track order progress in real-time”.
As the examples above show, features are small and standalone. Others companies might encompass both place and track the order as one feature. However, such an approach forces the Engineering team to deliver both for the feature to be complete.
In reality, if the “User can place order” feature is ready but “Track order real-time” isn’t, the former can still be released as a working, standalone feature to a production environment. It is the reason why a feature must be the smallest standalone piece of software which brings business value.
Writing a Feature
There is always a reason behind each feature. It is crucial to provide enough information for developers to understand the idea. When a feature is well-understood, it will give developers an excellent platform to work their magic on the implementation with the correct goals.
Product Managers used to write a “why” in each user story. However, it led to more downsides than benefits:
- Because of the repetitive nature of the task, Product Managers did not always share enough context.
- Important information about the “why” was sometimes too scattered across many small user stories.
To address those downsides, Product Managers now write the “why” at the feature level.
Providing Clear Context
Having the “why” at the feature level is an opportunity for Product Managers to put more thought into it while simultaneously spending less time working on it (by not having to write a “why” for every user story).
At the feature level, the “why” must be very clear and thoroughly detailed. It must outline:
- The need for the feature (i.e., what problem it aims to solve).
- How the feature aims to solve the problem (high-level only, details should live in the feature documentation).
- Any relevant context that may help developers make the right decisions when implementing the feature (e.g., dependencies on other features or third-party systems).
- Links to relevant resources and documentation.
Naming & Slugs
| Example | Name | Label |
|---|---|---|
| Users can view the list of tickets | User can list tickets | $user-list-tickets |
| Admins can view the details of a specific ticket | Admin can view ticket details | $admin-view-ticket-details |
| Agents can create new tickets | Agent can create ticket | $agent-create-ticket |
| Agents must assign a ticket to an agent | Agent must assign ticket | $agent-assign-ticket |
| Admins can delete an existing ticket | Admin can delete ticket | $admin-delete-ticket |
The naming for all features should follow a pattern that is somewhat similar to the user stories but in a shorter form.
The naming pattern, whenever possible, must be <user> <requirement> <action> <item> where:
-
<user>defines the type of user targeted by the feature. -
<requirement>should be one of: can, must (used to highlight a hard requirement for a user to accomplish something). -
<action>should be one of: list, view, create, delete. -
<item>defines the item that is being developed.
When following this pattern is not possible, feature names should always be descriptive. Generic feature names are frowned upon. For example, if a pricing feature needs improvement, creating a feature named “Improve price display” is virtually useless as it doesn’t describe the update. Moreover, when multiple iterative improvements are being made to a feature a name such as “Improve price display” becomes useless and confusing.
Instead, be descriptive. If the menu feature needs to notify users when the price changed then the feature should be named “User can see notification when the prices changed”. This name is descriptive and helps understand the feature at a glance.
In addition to having a name, features also need a slug for use in labels. The slug is a shorter, more condensed form of the name.
When feature names can follow the recommended pattern, the slug pattern should be <user>-<action>-<item>.
When a feature name can’t follow the recommended pattern, its slug should follow the same ideology being short and condensed. For example: user-price-changed-notification.
In Practice
Below is a complete example of a feature:
Module: Order Management
Feature: User can view their past order
Labels: #order-managment $user-place-order @1.2.0
## Why
Returning customers want to quickly reference their previous food orders to reorder favorites, or resolve order issues. Without easy access to order history, customers spend time searching through emails or calling restaurants, leading to frustration and potential order abandonment. Order history with reorder functionality reduces friction for repeat purchases and increases customer lifetime value.
To make this happen, we need to build the order history feature:
- Display past orders
- Allowing user to filter the order list by time or status
- Showing the order details
- Allowing users to reorder with the same selection and information
Keep in mind that we need to handle the case when the product prices are changed, or users try to order from a closed restaurant.
## Documentation
- Feature documentation: https://www.notion.so/nimblehq/feature-documentation-link
Versions
Versioning software is a basic principle (this very documentation is versioned on GitHub). In the backlog, each user story must be associated with a released version to facilitate tracking and debugging.
Versions are identified by the label @x.x.x where x.x.x is the actual version number. For example, all user stories released as part of version 1.2.2 must have the label @1.2.2.
For the versioning numbers, the team follows Semantic Versioning best practices with the following format MAJOR.MINOR.PATCH:
- MAJOR: when making backward incompatible changes.
- MINOR: when adding functionality that is backward compatible.
- PATCH: when making bug fixes that are backward compatible.
User Story Types

The team uses three types of user stories, even if a given backlog management tool offers more (or customizable) types: “User Story” (called “Feature” in some tools), “Bug”, and “Chore”.
Priority
Sprints should always be planned with the intent of completing all the stories. However, the Product Manager can determine the prioritization of the stories using the priority field. All projects should have the following priority fields setup:
- High: The story has a higher priority, it needs to be picked up before other stories.
- Medium: The default priority.
- Low: Other stories with higher priority can be picked up first.
High
If a story is time-sensitive, meaning it needs to be addressed immediately and has consequences if not done so, it should be assigned a High priority. Developers should always prioritize high-priority stories over medium and low priorities. Examples of a high priority are:
- Users are unable to login.
- An API endpoint is not responding.
- Credentials have expired.
- The contact details on the website are no longer valid and needs to be changed immediately.
- A hotfix that needs to be pushed to production.
- Adding a functionality that unblocks another feature being worked on in the same sprint.
Medium
By default, all tasks should be assigned a Medium priority.
Low
If a story needs to be completed in a sprint and there is no urgency, it should be assigned a Low priority. Developers can prioritize other stories before a low-priority story.
Examples of a low priority are:
- Minor changes to a UI element.
- A chore to cleanup code that is not critical.
- Writing documentation on a feature.
Labels
Labels (or tags) are heavily used in the backlogs. They help represent the backlog’s organization (with variations between backlog management tools) and any other sort of data visualization. It is important to use labels (there is no overuse) whenever something important needs to be tracked or presented.
For example, should there be a Request For Change for a product, the associated user stories should be labeled with the RFC number following the format rfc-<number>.
While there are a number of standardized labels, all labels don’t have to be standardized. It is at the Product Manager’s discretion to create and maintain relevant labels in their backlogs.
Standard Labels
There are a handful of standardized labels that are used throughout most backlog management tools.
- Module label. Its pattern is
#<module-name>. Example:#authentication. - Feature label. Its pattern is
$<feature-name>. Example:$user-list-tickets. - Chore label. Its pattern is
!<chore-name>. Example:!setup-ci-cd. - Version label. Its pattern is
@<semver>. Example:@1.2.2.
Those standardized labels are not necessary with every backlog management tool but, when they are necessary, they must follow the above patterns.
Format
The use of a symbol for the standardized labels allows for better sorting.
For example, when sorted alphabetically (a default in most tools), the modules authentication and user-profile would likely not be listed consecutively. Other labels would likely be in the middle.
Using a symbol forces the standardized labels to be listed consecutively. In the example above, #authentication and #user-profile will appear with all other module labels without others in-between.
Initial Label
As all projects must start with an exhaustive backlog, all the initial user stories must be labeled initial-scope. It will help later on with differentiating the initial project scope and the changes that made their way into the backlog and to the product. This label will give a snapshot of the project at its early stage.
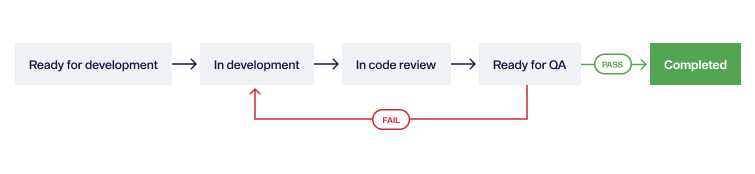
Workflow
Taking a user story from “new” to “completed” requires going through a few specific steps. The team’s implementation workflow has five steps:
| State | Description |
|---|---|
| Backlog | User stories that are not yet ready to be scheduled or even reviewed by the Engineering team. For example, ideas that the Product Manager doesn’t want to forget but require further research or preparatory work. |
| Ready for Development | The user story has been scheduled and developers can pick it up and start implementing it. |
| In Development | A developer has picked up the user story and is currently working on it. |
| In Code Review | The developer finished the implementation and the code is being reviewed by peers. |
| Ready for QA | The code has been successfully reviewed and was accepted requiring a round of manual Quality Assurance (QA). |
| Completed | Quality Assurance has been done and the user story was deemed complete and finished. |