
For developers new to Elixir and Erlang, there is an immediate impulse to use GenServer or Task for all purposes, including asynchronous jobs. Indeed, most web applications require some sort of mechanism to process tasks in the background, and GenServer or Task seems to fit all the requirements. So, is using GenServer or Task always the best option?
TL;DR
- Pick Task or GenServer for simple asynchronous jobs for which data persistence is not required.
- Pick Oban (backed by PostgreSQL) or Verk (backed by Redis) for advanced asynchronous jobs for which data persistence is required.
To better illustrate the issues a team can face when choosing a tool for processing background jobs, let’s take the example of an application which core feature is to fetch results from scraped Google search result pages.
Below is the overview diagram for the example application:
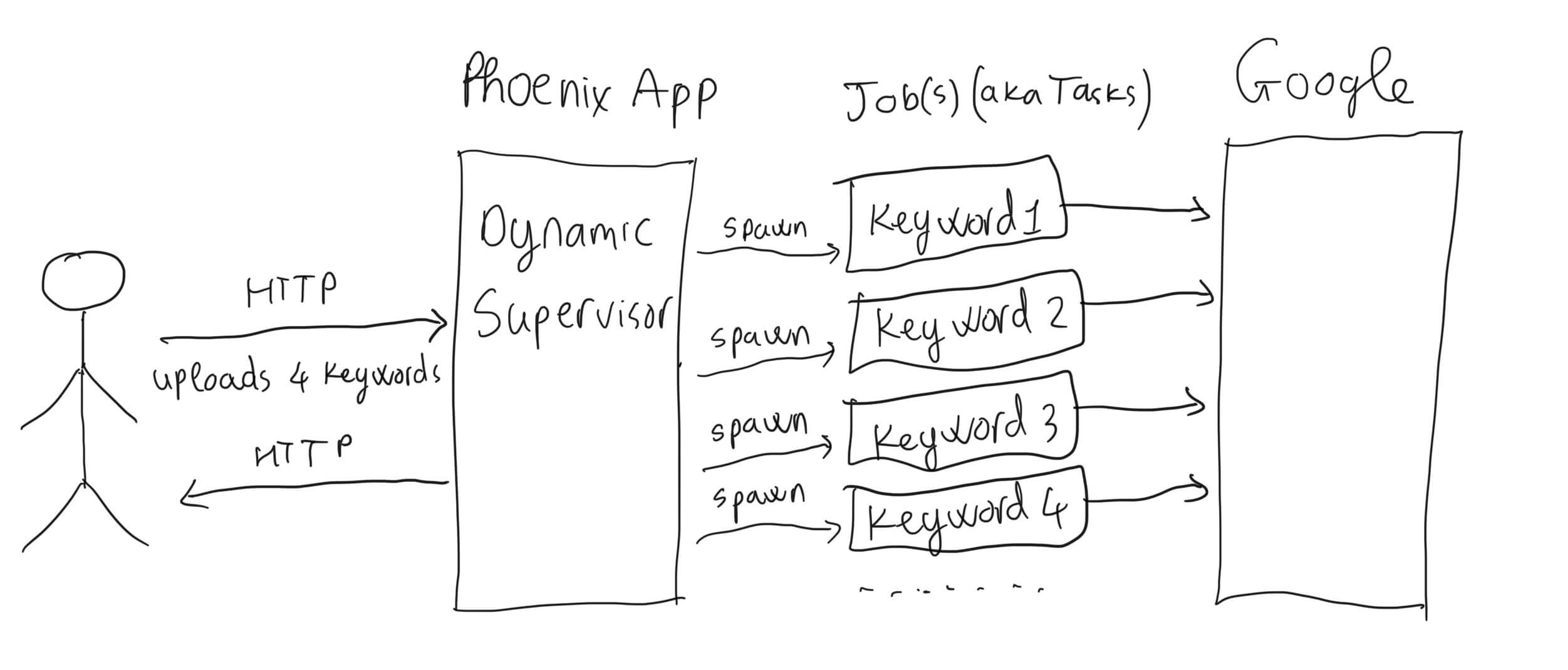
Let’s name our fictional team, the Alchemists. 🧙♀️
Task
Armed with their knowledge about Task Supervision, the Alchemists decide to use it to implement the aforementioned core feature application. So when a user uploads a keyword, the Task Supervision spawns a new Task to query Google and scrap the Google search results page asynchronously. It works well.
However, if the server is restarted for some reason, the job data will be lost since it has been stored in memory only. So, in this case, all the unfinished jobs would be gone, and the user would never get the results for the affected keywords.
Data Persistence
To fix the data persistence issue, the Alchemists decide to persist the job data into a database. Initially, the issue seems solved. Everything seems to be solved. However, the team quickly has to face a novel issue when executing a performance testing.
Concurrency Limitation - System Resources Are Exhausted
Before jumping into the novel issue, let’s take a detour to look at the application architecture.
To allow a user to search as many keywords as possible simultaneously and get results quickly, the Alchemists opted to start as many asynchronous tasks as possible. Each keyword has a dedicated asynchronous task. So, for example, if a user uploads 100 keywords, then 100 jobs would be running concurrently. The concurrency model in Elixir/Erlang makes this trivial.
At first, the system works well when processing a few users and a few keywords. But when many users upload several keywords simultaneously, several jobs would be created, causing the application to run into database connection issues. Every database limits the number of active connections. For instance, the Heroku free Database tier allows a maximum of 20 connections, so when the limit is reached, the jobs cannot connect to the database and fail due to a database connection timeout error.
During high peaks of traffic, when spawning an increasing number of jobs, both CPU and RAM can be overdrawn, causing the server to run out of memory, and consequently, taking the application down.
Worker pool
The Alchemists decide to limit the number of jobs by creating a worker pool using poolboy to solve the system resource exhaustion.
The application now creates fewer jobs running concurrently. Therefore, there are no database connection issues, and the RAM and CPU are not overdrawn. Everything works perfectly. 🎉
Unfortunately, a new issue quickly appears. As the asynchronous jobs execute several requests to Google search, the application must now handle Google’s rate-limiting protection mechanism, which is triggered when a high number of requests are coming from a single source. This causes failures for some keywords search as the search requests are denied by Google.
To solve the rate-limiting issue, the Alchemists opt to throttle the number of requests performed in a period, for example, 30 requests in one minute. That’s where GenServers come into play.
GenServer
The Alchemists implement a separate GenServer to monitor the execution of the asynchronous jobs. The GenServer is in charge of controlling and limit the number of requests made in a configurable period.
The GenServer and the worker pool that were implemented earlier now allow the application to fulfill all keyword search requests. 🎉
Draining mechanism
The application works well. However, there is still one hot issue on the table. What happens to the list of in-progress jobs on the next deployment? These jobs cannot just simply be interrupted. We now need a new draining mechanism to fulfill all search requests gracefully.
The Alchemists now realize that managing an efficient background job is getting very complicated. The team has spent a lot of time to solve many issues along the way. Is there a third-party package on Hex that would solve all these issues?
Oban
Fortunately, there is a library called Oban which provides a robust solution to all the issues faced by the Alchemists:
- Isolated and Resilient Queues.
- Queue Control.
- Job Cancelation.
- Unique Jobs.
- Scheduled Jobs.
- Job Priority.
- Job Draining.
- Job data persistence.
- Job retries.
- Concurrency Throttling.
- Telemetry/Metrics.
- Battle-tested on production.
The team opted to replace their custom implementation with Oban. And with a few configuration settings, the team now has a robust background job system. 🎉
Summary
By going through this journey, the Alchemists have learned a lot about Elixir-built-in features - such as Task, Task Supervision, GenServer - and also the intricacies of background jobs. While these built-in Elixir features can be used for asynchronous jobs, Oban (backed by PostgreSQL) or Verk (backed by Redis) are recommended to build a robust background job system in an Elixir application.
If you are in need to build or manage your Elixir application, Nimble offers development services for Elixir and Phoenix.
References